无论是AD/ADAS还是智能网联车,前视感知都是其最基础和重要的能力之一。无人驾驶(AD)是前几年的热门话题。今天虽然稍微降温下来一些,但仍是大家关注的重点之一,毕竟它是人类长久以来的梦想之一。众所周知,美国汽车工程师学会(SAE)将无人驾驶分为L0~L5共六个级别。其中L3及以上允许由系统在限定或不限定条件下完成所有的驾驶操作;而L2及以下还要由人类驾驶员从始至终保持驾驶状态,因此大多还属于高级驾驶辅助系统(ADAS),如车道偏离预警(LDW),前碰撞预警(FCW),自适应巡航(ACC),紧急自动刹车(AEB),车道保持辅助(LKA),交通标志识别(TSR),自动泊车(AP)等。和大多数智能机器人一样,无人驾驶的处理流程可分为三个阶段:感知、决策、执行。因此一旦感知出了问题,那后面基本就凉了。类似地,ADAS或AR导航也强依赖于对环境的感知。没准确且实时的感知能力,上层做的再炫酷也容易成为鸡肋。ADAS和AD间的界线并没那么清晰,前者可看作到后者的过渡产品,因此很多技术是通用的。前视感知是个非常大的话题,因此本文主要聚焦在一些最为基础和通用的前视感知能力上。
本节我们从工业界和学术界两个方面简要聊下业界的相关情况。它们各有优缺点,学术界涌现出更前沿更先进的方法,且指标明确,易于定量比较,但方法往往专注于单点,且对实际产品中的各种约束(如计算资源)考虑不多;而工业界直接面对产品,更多地考虑实用性和整体性。但采用的指标、数据不透明,难以衡量和比较。只有全方面的了解,通过产学研的加速融合,才能打造更完善、更好使用者真实的体验的产品。
ADAS有着几十年的发展历史。国内外都有一大批优秀的厂商。这几年,随国家驾驶安全政策的推动和无人驾驶技术受到热捧,该领域出现了快速的增长。从老牌劲旅Bosch、Continental、Aptiv,Mobileye等,到一批相对年轻但很存在竞争力的公司如Maxieye、Minieye、魔视、极目、纵目、Nauto等,这是一个既成熟,又充满机遇的市场。根据中投顾问的《2017-2021年中国汽车高级驾驶辅助系统(ADAS)市场深度调研及投资前景预测报告》,ADAS年复合增长率将达35%,2020年中国市场可实现近800亿市场空间。近几年,车载AR导航将传统的ADAS功能与导航功能、AR技术及HUD进行了融合,带来了更直观和人性化的使用者真实的体验,成为了市场的热点。在实现方式上,各家在传感器配置上也各有不同,有摄像头、毫米波雷达、激光雷达等。其中,基于摄像头的视觉方案由于其成本可控、算法成熟等优点,使用最为广泛。其中的主要代表如Mobileye和Tesla Autopilot都是主要是基于视觉的方案。


虽然ADAS细分功能众多,但很多功能功能(LDW,FCW,LKA,ACC等)都依赖于对前方环境中几个基本对象的检测和识别,即车道线、物体(包括车辆、行人、障碍物、交通灯、交通标识等)、可行驶区域,因此本文也会主要聚集在这几类对象的检测识别上。在准确率上,各家的产品往往很难量化及横向比较,尽管大家的宣传中常会出现“准确率XX%”或者“误报率/漏报率X%”这样的提法。但事实上由于指标定义和数据集的差异,很难做到“apples to apples”的对比。有些比较实在的会采用相对指标,比如与行业标杆(如Mobileye)在同样的数据集上做横向对比。这样会更有说服力。但因为所用数据集未公开,别人也很难严格横向比较。在性能上,由于ADAS对检测的实时性要求非常高,所以很多至少会做到15 FPS以上。随着深度学习的兴起,慢慢的变多的ADAS厂商也将基于传统CV的方案慢慢地过渡为基于深度学习的方案。深度神经网络(DNN)的推理需要很大的计算量,而ADAS不像高级无人驾驶平台配备强大的计算平台,因此业界的趋势之一是利用专用硬件(如FPGA或ASIC芯片)来进行加速。
在学术界,无人驾驶一直是经久不衰的热点之一。这一些方法上的创新很多同样也能够适用于ADAS和AR导航中。我们大家都知道,2012年以来深度学习的加快速度进行发展使其成为机器学习中的绝对主流。基于深度学习的方法同样也给无人驾驶带来了巨大变革。基于传统CV算法的方法在泛化能力上容易遇到瓶颈。经常是在一段路段调优跑溜后,换一段路又需要大量调参。当然,基于深度学习的方法也无法完全避免这样的一个问题,但能够说是大大缓解了。学术界的优点就是较为透明公开、且容易对比。新的方法就是需要在与其它方法比较中才能证明其优异,因此历史上通过竞赛的方式来推动发展的例子不在少数。2004年开始,由DARPA主办的几场无人车挑战赛开启了无人车的新时代。在深度学习时代,各种针对路面环境检验测试识别的榜单就如同ImageNet一样,催生出一大批新颖的方法。其中针对车道线、物体和可行驶区域的很典型的有:
KITTI:2013年由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,是一套非常全面的算法评测数据集。其中覆盖了2D、3D物体检测,物体跟踪,语义分割、深度估计等多种任务。但其数据集数量在现在看起来不算多,如物体检验测试的数据集训练集和测试集总共1W5张左右,车道检测就比较尴尬了,只有几百张。
CVPR 2017 TuSimple Competitions:2017年图森未来主持的挑战赛,分车道线检测和速度估计两个任务。其中车道线检验测试的数据集包含了几千张主要是高速上的数据。虽然量不多,但因为和物体检测这类通用任务相比,针对车道线检测的竞赛很少,所以它至今在很多车道线检测的论文上还会被当成量化比较的重要参考。
CVPR 2018 WAD:由Berkeley DeepDrive主持,包含三项赛事:道路物体检测,可行驶区域分割和语义分割的域适应。它基于BDD100K数据集。这是一个在数量和多样性上都相当的好的用于无人驾驶的数据集。其中用于物体检测和可行驶区域分割的数据集共有10W张左右,其中训练集和验证集有约8W张。
Cityscapes:针对道路环境的经典语义分割数据集,同时也提供了语义分割、实例分割和全景分割任务的榜单。数据集采自50个城市,包含了5K张精细标注图片和2W张较粗糙标注图片。考虑到语义标注的成本相对大,这个数量已经算比较大了。
其它的榜单还有很多,无法一一列举。虽然由于大多榜单只关注准确率导致其模型很难直接落到产品中,但其中确实也出现了非常多精巧的方法与创新的想法,为产品落地提供了有价值的参考。关于具体的方法我们留到后面专门章节进行讨论。
还有一些介于工业界与学术界之间的工作,它们将学术界的成果向产品逐渐转化,提供了参考实现。很典型的有开源无人驾驶项目Apollo和Autoware。因为它们主要面向无人驾驶,所以会除了摄像头之外,还会考虑激光雷达、毫米波雷达、高精地图等信息。由于本文的scope,这里只关注基于摄像头的对基础对象的检测。Apollo 2.5中采用的是一个多任务网络检测车道线与物体(之前读代码的一些笔记:无人驾驶平台Apollo 2.5阅读手记:perception模块之camera detector),对于车道线模型会输出像素级的分割结果,然后通过后处理得到车道线实例及结构化信息(相关代码阅读笔记:无人驾驶平台Apollo 3.0阅读手记:perception模块之lane post processing);物体检测是基于Yolo设计的Yolo 3D,除了输出传统的2D边界框,还会输出3D物体尺寸及偏转角。版本3.0(官方介绍:perception_apollo_3.0)中加入了whole lane line特性,提供更长距的车道线检测。它由一个单独的网络实现。3.5中将物体与车道线检测网络彻底分离,车道线模型称为denseline。最新的5.0(官方介绍:perception_apollo_5.0)中又引入DarkSCNN模型,它基于Yolo中的backbone Darknet,并引入了Spatial CNN(后面再介绍),同时该网络中还加入了对灭点的检测。Autoware中车道线用的是传统CV的方法,物体检测基于摄像头部分使用的是SSD和YOLO等基于深度学习的方法(官方介绍:Overview)。
我们知道,深度学习有三大基石:数据、算法和算力。对于基础前视感知场景,我们也从这三个维度来聊一下。在此之前,我们先列下本文关注的单目基础感知主要流程:
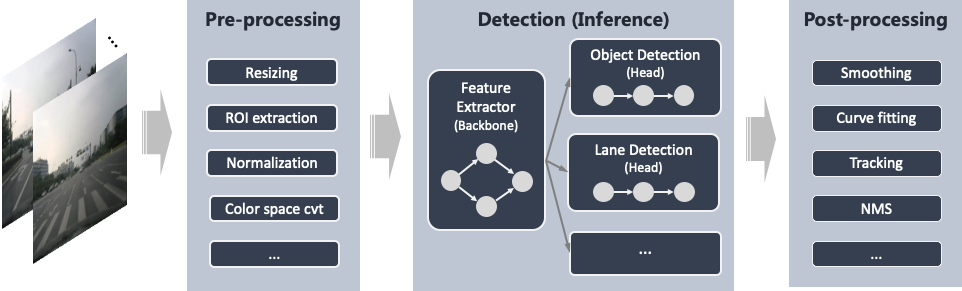
预处理:这一阶段主要是做必要的数据处理,为后面的检测准确好数据。如一些摄像头进来的视频流是YUV格式,而深度神经网络模型输入多是RGB格式,有必要进行转换。此外,很多模型会要求输入数据作归一化。另外,为减少计算量,一般还会对输入的图像进行缩放和ROI的提取。
检测模型推理:这一阶段主要是做深度神经网络的推理。对于要同时完成多个任务的场景,我们一般会使用多任务网络。即每个任务对应一个网络分支输出,它们共享用于特征提取的backbone(按经验很多时候backbone会占大部分的计算量)。近年学术界也出现一些对不一样任务比较通用的backbone结构。
后处理:这一阶段是将前面推理得到的结果进行进一步的处理,以传到后面的决策或展示模块。常见的对于车道线需要滤除噪点,聚类,曲线拟合,滤波(如Kalman filter)等;对物体检测常见的有非极大值抑制(NMS)和跟踪等;对可行驶区域,需要将分割结果转为多边形并确定其位置类别。
注意这里只画了简化的部分流程。实际场景中,可能还需要仔细考虑非常多其它元素,比如:
相机标定(Camera calibration):我们在学车考“S弯”或者“单边桥”等项目时,教练往往会告诉我们一些小技巧,如通过雨刮器的位置来估计轮胎的位置。这种技巧其实比较脆弱,因为座椅的调整,人的高矮都会影响其精确度。那在ADAS/AD场景中如何告诉机器以高精度做这件事呢,是通过相机校准。这本质是做图像坐标和世界坐标之间的转换。另外,有了校准参数,我们还可以用它做逆透视映射(IPM),消除透视带来的影响,方便车道线检测及物体跟踪等模块。
光流(Optical flow):每一帧都检测会带来非常大的计算开销。有时我们会通过光流算法来计算图像中像素点的瞬时速度,从而估计已检测对象在当前帧的位置。这样一方面能有实际效果的减少计算量,另一方面还能用于物体的跟踪。
灭点(Vanishing point):我们大家都知道,由于透视关系,平行的线(如车道线)在远处会交到一点,称为消失点或灭点。这个点对于车道检测或最后的可视化都有帮助。在直线的情况下,我们大家可以通过车道线的交点来估计灭点,但如果车道线是不太规则的曲线,就比较麻烦,需要通过更复杂的方法进行估计。
测距:不少ADAS功能中都需要确定前方物体的距离。常用毫米波和超声波雷达做距离检测。而在纯视觉方案中,双目方案是根据视差来估计距离,原理就像人的两只眼睛一样。而对于单目方案就比较tricky一些,需要检测物体后根据物体下边界结合相机标定计算距离。现在虽然有基于单张图像的深度估计方法,但那个本质上是靠的训练所获得的先验,用作ADAS里的FCW啥的感觉还是精度不太够。
3D姿态估计(3D pose estimation):高级点的前视感知对物体检测除了边界框,还会估计其姿态。这对动态障碍物的行为预测非常有帮助。
细粒度识别(Fine-grained recognition):对于一些识别的物体,如果它们的类别会影响到驾驶行为(如交通灯、交通标志、车道线等),则我们需要将检测结果中相应部分拿出来进一步对其进行分类识别。
决策和展示:所有的检测都是为了最后的决策和展示。如何自然地显示(如通过AR展示的话如何与现实物体贴合),以及何时预警或介入控制都直接影响用户体验。
另外可能还需要检测路面上的指示标记,以及对当前场景是否支持作检测判断等等。由于篇幅有限和使内容简洁,这些本文都暂不涉及。检测对象上本文主要关注车道线、物体和可行驶区域。
我们知道,深度学习的最大优势之一就是能对大量数据进行学习。这就意味它的效果很大程度上依赖于训练的数据量,而对于汽车的前视感知更是如此。因为汽车的环境是开放的,没有充分而多样的数据,模型便无法有效地泛化,那在各种corner case就可能出岔子。对于其它场景出岔也就出岔了,对AD或者ADAS来说那可能就危及生命安全了。数据集大体有两类来源,一类是公开数据集;一类是自标数据集。它们各自有优缺点。
包含可行驶区域的有BDD100K,KITTI等。虽然理论上语义分割的数据集(如Cityscapes)就包含了可行驶区域的标注,但比较理想的标注还应该区分当前车道和相邻车道。
其它的还有不少数据集,网上有很多列表整理,这里就不重复了。虽然这些数据集很丰富,但有时未必能直接用上。一方面是它们的标注之间有很大差异。其中一个差异点是标注格式,这个其实还好办,脚本基本能搞定。比较麻烦的是有时候标注的规范和内容会有出入。以车道线为例:有些是采用双线K),有些是单线标法(如CULane,TuSimple Lane Challenge);有些是标有限条(如CULane),有些是有多少标多少(如BDD100K);有些对于虚线是像素级精确标注(ApolloScape),有些是会将它们“脑补”连起来(CULane);有些标了车道线K),有些没有标(CULane)。而对于车辆和行人来说,不同数据集有不同的细分类。但本着人家标注也不容易,能用上一点是一点的精神,可以尽可能地对它们进行转化,使它们一致并满足特定需求。举例来说,BDD100K中是双线标注,而其它多数是单线标。为了统一,我们能够最终靠算法自动找到匹配的线并进行合并。自动合并效果如下:

公开的数据集虽然方便且量大,但往往没法完全满足需求。比如由于地域差异、摄像头差异等会导致domain shift问题,另外有些针对性的case没法覆盖。公开数据集另一个问题是license。很多的公开数据集只能作研究用途,如果要商业用途是禁止或者需要专门再购买license的。因此,实际中往往还是需要请外包或自己标数据。
数据增强(Data augmentation):最基本也很有效的扩充数据集手段之一,在车辆环境中尤为重要。由于道路环境数据集需要多样化,因此我们应该通过数据增强来模拟不同的光照、天气、视角等变化。
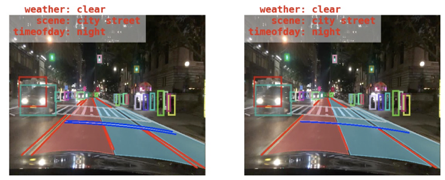
自动标注/辅助标注:虽然移动端上由于算力有限,我们只能牺牲准确率布署轻量级的网络,但我们可以训练重量级的精度较高的网络模型用于对数据来进行自动标注。以下是一个重量级网络(不是SOTA的)在BDD100K上训练后的检测效果。虽然不是十全十美,但在有些小目标上可能比老眼昏花的我还要标得凑合。就算无法完全替代人肉标注也可以作为辅助有效减少人工。

图5 某重量级网络在BDD100K数据集上检测效果(左:检测结果;右:Ground truth)
仿真器:利用仿真器来帮助自动驾驶测试似乎已经是一个普遍性做法了。随着3D图形技术和硬件的飞速发展,今天仿真器中的渲染效果已相当逼真,已经不像当年赛车游戏里车后冒个烟还是“马赛克”效果。因此,仿真器也有望用于产生可用于训练的数据。
生成对抗网络(GAN):我们知道,GAN是最近几年非常火热的一个方向。GAN也在一些工作中用于训练数据的生成。虽然目前很多时候是看demo各种牛,但实际跑的时候可能就不是很理想。但不可否认这是一个很有前途的方向,不少工作应用它来缓解数据多样化需求的问题。
针对前视感知中的几类目标,算法是不同的。另一方面,我们知道深度学习的视觉领域研究比较多的任务是:图片识别、物体检测、图像分割(包括语义分割、实例分割、全景分割)。那么问题来了,如何将对现有任务的方法充分应用来满足前视感知的需求?如果实在不合适如何调整?
首先是车道线检测,这可能是几类检测目标中最特殊的,所以占的笔墨也会相对多些。它的特点是形状狭长(可能跨越大半张图片),并且形态多变(可能是直线也可能是曲线,还可能交叉等),容易与路面标识混淆,另外还需要区分实例。现有物体检测的方法不太适合这种形状的东西。我们知道,在深度学习占领视觉领域前,车道线检测多采用传统CV的方法。Udacity(其联合创始人Sebastian Thrun是自动驾驶界大神)上有一个自动驾驶课程。其中有作业就是车道线检测,因此网上有很多这个作业的实现。其中比较关键的几步是通过边缘检测算法(如Canny,Sobel算子)得到边缘,然后通过Hough transform检测直线(如果假设车道线为直线),或者经过IPM得到鸟瞰视图后通过滑窗搜索得到车道线上的像素点,最后多项式曲线拟合输出。这里边几乎每一步都有不少参数,而且各步相互影响,如果场景很多样化的话调参就可能会比较酸爽,另一方面它对于车道线不完整的情况(如因遮挡或磨损)表现不好。因此,这已经不是目前的主流,后面业界逐渐过渡到基于深度学习的方法。
2015年,深度学习风头正劲,Stanford、Twitter等机构联合发表的论文讨论了将CNN应用到高速环境的车道线]。它使用当时物体检测的方法[2]来检测车道线。因为车道线很长条,因此被分成多个线段,每个线段被当成物体来检测。最后通过DBSCAN进行聚类得到车道线实例。同期另外一条思路是将车道线检测当作语义分割任务。当时语义分割领域有了FCN[3]、SegNet[4]和DeepLab[5]等早期经典网络。结合一些包含车道线标注的语义分割数据集便可以进行车道线]试图将包括车道线在内的多种检测任务在分割任务中一把搞定。然而故事还远没有结束,这里还存在以下两个比较大的挑战,接下去几年的工作也是主要围绕这两点来展开:
繁琐的后处理:现实中我们为了后面的决策还需要知道哪条是当前车所在车道(Ego lane)的左、右车道线和相邻车道的车道线。另外,因为车道线往往不完整,因此还需要得到车道线的结构化表示(如多项式或样条曲线)以便做插值。这样,单就语义分割的结果还不够。以往常见的做法是将分割结果进行聚类得到实例,然后通过一些后处理判断其是哪条车道。另外,为了得到结构化表示还需要对这些点进行多项式拟合等操作。理想的方法是简化或完全去除这些后处理,实现真正意义上end-to-end的检测。
复杂的环境:路面环境复杂常常导致图像中的车道线残缺不全。如天气因素,其它车辆遮挡,阴影和光照,磨损等等。另外的一个比较大的干扰来自于地面上的箭头指示和汉字,仅看局部图像的话人也难以区分。因此如果无法有效利用全局上下文信息很难对它们进行排除。对这些因素做到足够鲁棒是通往实用产品的必要条件。
来自三星的论文[7]将车左右两条车道线作为两个类别(加上背景共三类),从而直接通过神经网络来学习,相当于做了实例分割,从而简化了后处理。
2017年TuSimple主办了车道线检测竞赛,炸出不少好的方法,同时也成为了车道线检测的重要benchmark之一。第一名来自香港中文大学,它也是基于语义分割来做,并针对车道线这种狭长的物体提出了Spatial CNN(SCNN)[8]来替代MRF/CRF来对空间关系进行建模。另一个比较有意思的点是当时竞赛提供的数据集才几千张(标注图片约3.6K),因此数据可能会成为主要瓶颈之一,于是他们整了一个大规模的车道线的数据集CULane。该数据集共有13W多张。它比较贴近现实情况,涵盖了白天、晚上、拥堵、阴影、光照过亮等9种场景。对于车道线的实例区分问题,SCNN由于限定最多检测4条车道线条车道线类物体来检测。同时,网络还有一个专门的分支用于预测对应的车道线是否存在。这样便不需要聚类来提取实例。当时的第二名来自佐治亚理工(Georgia Institute of Technology)等机构。他们提出的方法[9]可以解决只能处理有限车道线的问题。它利用像素对之间的关系,通过对目标函数的巧妙构造,让神经网络学习像素的聚类信息。并且可以拓展到(理论上)无穷实例的场景。
2017年韩国KAIST和三星提出了VPGNet[10]。它是一个多任务网络,其中一个分支用于预测灭点,它可以引导车道线的检测。这在一些恶劣的天气下可以有比较大的帮助。但这需要额外标注的数据集。论文中提到他们建立了自己的数据集但没有公开。
2018年,鲁汶大学(KU Leuven)的论文提出LaneNet[11],它将车道线检测作为一个实例分割问题。以前很多方法对于提取车道线实例是用聚类,而对于车道线这种狭长的物体很难定义一个好的距离测度用于聚类。这篇论文的最大特色就是在传统语义分割分支外还加了一个pixel embedding分支,用于对输入图像中的每个点得到其N维的embedding,这个分支是基于其实例信息训练的。语义分割输出的像素结合pixel embedding信息,作聚类后便可得到车道线的实例信息,最后通过多项式拟合输出。鲁汶大学这个团队次年在论文[12]中把预测曲线与ground truth曲线间的面积作为损失函数,将拟合改造成可微分操作,从而让神经网络来学习拟合曲线的参数。前面LaneNet这篇论文另一个比较有特色的点是H-Net。IPM有利于车道线的多项式拟合。因为大多数弯曲的车道线在鸟瞰视图下用二次曲线就够了,但在透视视图下却需要更高阶曲线才能拟合。而这个变换的参数一般需要通过相机标定。但是这个参数可能根据地形、坡道因素不同。因此最好可以根据输入动态调整。H-Net采用通过神经网络来预测的方式。这条思路上类似的工作还有来自2018年GM的3D-LaneNet[13]。该方法以end-to-end方式直接预测3D的车道线。网络采用dual-pathway结构。一条对应普通透视图,估计逆透视变换参数。该参数结合前面的feature map与另一条对应鸟瞰视角的网络中feature map结合,最终输出3D车道线D车道线标注的数据集不好弄,于是他们自己搞了个高速场景下的合成数据集作了实验。因此该方法在真实场景下的效果还需要进一步验证。
杜克大学和地平线提出的LaneNet[14](也叫LaneNet,但此LaneNet非彼LaneNet)将车道线检测分为两个阶段-lane edge proposal和lane line localization。前者是一个语义分割网络;后者是比较特色的地方,其网络基于LSTM,输出为各条车道线的信息。因此,某种程度上替代了很大部分后处理。
TomTom公司提出的EL-GAN[15]通过GAN的思想来改善语义分割的结果。单纯的语义分割应用于车道线所得结果不会考虑其平滑或是邻域一致性等。EL-GAN在GAN的基础上添加了embedding loss通过discriminator让语义分割的输出更接近ground truth。直观上这样语义分割的结果就会更符合车道线的拓扑形状特征,从而减化了后处理的工作。
我们知道,对于视觉任务,有两个比较通用的思路是可以帮助提高准确率的。一个是注意力(Attention)机制。今年由香港中文大学等机构发表的论文[16]提出了Self Attention Distillation(SAD)方法。它基于注意力蒸馏(Attention distillation)的思想,将之改造为自蒸馏,从而不依赖传统知识蒸馏中的teacher model。网络中后面的层的feature map(具有更丰富上下文信息)作为监督信息帮助前面的层训练。前面的层学到更好的表征后又会改善后面的层,构成良性循环。另一个是用RNN结合前后帧信息。武汉大学和中山大学的论论文[17]结合了CNN和RNN来使用连续帧进行车道线检测。网络结构中在由CNN组成的encoder和decoder间放入ConvLSTM用于时间序列上特征的学习。由于结合了前面帧的信息,在车道线磨损、遮挡等情况下可以做到更加鲁棒。
然后是物体检测,这块的算法可以说是相当丰富。因为物体检测的应用范围非常广,因此它几乎伴随着计算机视觉领域的发展。相关的survey很多(如[18],[19]等)。深度学习兴起后,一基于深度神经网络的物体检测算法被提出。SOTA以极快的速度被刷新。从two-stage方法到轻量的one-stage方法,从anchor-based方法到近年很火的anchor-free方法,从手工设计到通过自动神经网络架构搜索,琳琅满目,相关的总结与整理也非常多。
对于道路环境来说,几乎和通用物体检测算法是通用的。如果要找些区别的话,可能汽车前视图像中,由于透视关系,小物体会比较多。2018年CVPR WAD比赛其中有一项是道路环境物体检测。第一名方案来自搜狗,根据网上介绍(给机器配上“眼睛”,搜狗斩获CVPR WAD2018挑战赛冠军),其方案在Faster R-CNN的基础上使用了CoupleNet,同时结合了rainbow concatenation。第二名方案来自北京大学和阿里巴巴,提出了CFENet[20]。经典的one-stage物体检测网络SSD在多个scale下的feature map进行预测,使得检测对物体的scale变化更加鲁棒。小目标主要是通过浅层的较大feature map来处理,但浅层特征缺乏包含高层语义的信息会影响检测效果。CFENet针对前视场景中小物体多的特点对SSD进行了改进,在backbone后接出的浅层上加入CFE和FFB网络模块增强浅层特征检测小目标的能力。
现实应用中,物体检测模型的输出还需要经过多步后续的处理。其中比较常见和重要的是NMS和跟踪:
神经网络模型一般会输出非常多的物体框的candidate,其中很多candidate是重叠的,而NMS的主要作用就是消除那些冗余的框。这个算子很多的推理框架不支持或支持不好,所以一般会放到模型推理外面作为后处理来做。在学术界NMS这几年也出现了一些可以提高准确率的变体。
跟踪是理解物体行为的重要一环。比如帧1有车A和车B,帧2有两辆车,我们需要知道这两辆车哪辆是A,哪辆是B,或都不是。只有找到每个物体时间维度上的变化,才能进一步做滤波,以及相应的分析。比较常见的多物体跟踪方法是SORT(Simple Online and Realtime Tracking)框架[21],或许它的准确率不是那么出众,但综合性能等因素后还是不错的选择,尤其是对于在线场景。结合通过CNN提取的外观特征(在DeepSORT[22]中采用)和Kalman filter预测的位置定义关联度的metric,将帧间物体的跟踪作为二分图匹配问题并通过经典的匈牙利算法求解。前后帧物体关联后通过Kalman filter对状态进行更新,可以有效消除检测中的抖动。
再来说下可行驶区域。开过车的们都知道咱们的很多路没有那么理想的车道线,甚至在大量非结构化道路上压根儿就没有车道线。在这些没有车道线、或者车道线不清晰的地方,可行驶区域就可以派上用场。一般在可行驶区域中我们需要区分当前车道和其它车道,因为该信息对后面的决策规划非常有价值。
在这个任务上早期比较流行的榜单是KITTI的road/lane detection任务。很多论文都是拿它作benchmark,其榜单上有一些是有源码的。不过那个数据量比较少,多样化程度也不够,要用它训练得泛化能力很强实在比较勉强。
2018年CVPR WAD比赛中一个专项是可行驶区域检测。所用的BDD100K数据量相比丰富得多。当时的冠军方案是来自香港中文大学的IBN-PSANet。它的方案是结合了IBN-Net[23]和PSANet[24]。前者主要特色是结合了batch normalization(BN)和instance normalization(IN)。BN几乎是现代CNN的标配。它主要用于解决covariate shift问题,提高训练收敛速度;而IN可以让学习到的特征不太受像颜色、风格等外观变化的影响。而结合了两者的IBN可以吸收两者的优点。而PSANet的特色主要是提出了PSA结构,它本质是一种注意力机制在视觉上的应用。对于每一个像素,网络学习两个attention mask,一个对应它对其它每个像素的影响,一个对应其它每个像素对它的影响,从而使得分割可以充分考虑全局上下文信息。
可行驶区域检测中对于语义分割的输出比较粗糙,且形式不易于后面模块处理,因此还需要经过一些简单的后处理。比如先聚类,再计算各类簇的凸包,最后通过这些多边形的位置关系便可以确定它们是当前车道还是其它车道的可行驶区域。
值得一提的是,可行驶区域和车道线语义上是非常相关的,因此可以通过相互的几何约束来提高准确率。业界也有不少这方面的尝试,越来越多的深度神经网络将它们进行融合。
从算法到产品最大的鸿沟之一便是性能优化。移动端设备有限的算力正在与多样化算法的算力需求形成矛盾。这在之前写的文章《浅谈端上智能之计算优化》中进行过初步的讨论。对于像ADAS这样的场景实时性尤其重要。我们大家可以从文中提及的几个角度进行优化。
首先,在网络设计上我们在backbone上可以选择这几年经典的轻量级网络(如MobileNet系[25],[26],ShuffleNet系[27],[28],EfficientNet[29]等)。这些网络一般在计算量上比重量级网络有数量级上的减少,同时又可以保持准确率不损失太多。另一方面,对于多个检测任务,由于输入相同,我们一般会使用多分支的网络结构。每个任务对应一个分支(head),它们共享同一个用于特征提取的backbone。按经验来说,这个backbone占的计算一般会比较大,因此这样可以节省下相当可观的计算开销。但是这样的多任务多分支网络会给训练带来困难。最理想的当然是有全标注的数据集,但这样的数据集比较难获得。对于这个问题,我们可以采取两种方法:一种是如前面提的,靠重量级高准确率网络自动标注。如训练高准确率的物体检测模型给已有车道线标注的数据集进行标注;另一种就是对带特定标注的数据输入,训练对应的部分(backbone和相应的head)。
对于给定网络结构,我们能够最终靠模型压缩进一步减少计算量。因为普遍认为推理时不需要训练时那样复杂的模型和高的精度。模型压缩有很多种方法,有量化、剪枝、知识蒸馏、低轶分解等等。常用的方法之一是量化。一般来说,将FP32转为FP16是一种既比较安全收益又比较大的做法,然而在一些低端设备上我们还需要作更低精度(8位或以下)的量化。这时就得花更多精力在准确率损失上了。量化又分为post-training quantization和quantization-aware training。前者使用方便,不需要训练环境,最多需要少量(几百张)数据集作为量化参数calibration之用,但缺点是会对准确率损失较大;而后者,需要在训练时插入特殊的算子用于得到量化所用参数及模拟量化行为。另一种常用的压缩方法是网络剪枝。根据网络模型的敏感度分析,一些层稍作裁剪可能就会有大的准确率损失,而另一些层进行裁剪则准确率损失不大,甚至还会使准确率上升。这就给了我们简化模型从而减少计算量的机会。低轶分解本质上是通过对矩阵的近似来减少矩阵运算的计算量。知识蒸馏是一种很有意思的方法,就像现实中的老师教学生,通过teacher model来帮助训练student model。
网络模型敲定后,就需要考虑性能优化。深度的优化是离不开硬件的考虑的。对于一些用于无人驾驶的计算平台,可能直接就上像Nvidia的PX2这样的高性能硬件平台了。但对于普通车规硬件平台,肯定是扛不住这种成本的。这些常规车机平台中一些稍高端的会有几百GFLOPS的GPU处理能力,或其它DSP,NPU等计算硬件。这里我们一般会首选这些硬件做模型推理而非CPU。因为如果将这些计算密集型任务往CPU放,会和系统中其它任务频繁抢占资源导致不稳定的体验。而对于低端一些的平台GPU基本只够渲染,那只能放到CPU上跑,一般会用上面提到的量化方法将模型转为8位整型,然后将推理绑定到固定的核上以防止影响其它任务。推理引擎有两类选择。对于一些有成熟推理引擎的硬件平台,使用厂商的引擎(如Intel有OpenVINO,高通有SNPE)通常是一个方便快捷的选择;还有一种方法就是用基于编译器的推理引擎,典型的如TVM。它以offline的方式将网络模型编译成可执行文件并可进行自动的执行参数优化。至于哪个性能好,通常是case-by-case,需要尝试。值得注意的是,上面选取的轻量型网络一般是memory-bound的,因此优化时需要着力优化访存。
如果平台上有多种可以执行神经网络算子的硬件,如CPU、GPU、NPU、DSP,那可以考虑通过异构调度来提高硬件利用率,从而达到性能的优化。现在业界已有不少的异构计算框架,如ONNXRuntime,Android NN runtime等。这里面,最关键核心的问题在于调度。对于单个网络模型而言,先要对网络进行切分,然后分配到最合适的硬件上,然后在每个硬件上进行本地调度。难点在于这个调度是NP-hard的,意味着对于实际中大规模问题,不可能在合理时间找到最优解,而要找到尽可能优的近似解是门大学问。业界出现了大量的方法,如精确算法、基于启发式策略、元启发式搜索和机器学习的方法。对于前视感知任务中的多分支模型,一个最简单而有效的做法就是将backbone以及各个head的分支作为子图进行切分和调度。如果要得到更优的调度,则可以进一步尝试基于搜索和学习的方式。
前视感知领域是一个小打小闹容易但做好非常难的东西。它需要长期的沉淀才能构建起核心竞争力和技术壁垒。我们看到今天行业龙头Mobileye独领风骚,但少有人看到它在早期的执着。Mobileye创立于1999年,但到2007年才开始盈利。类似的还有谷歌的无人驾驶车(差不多10年了),波士顿动力的机器人(貌似27年了),还有许许多多这样“耐得住寂寞”的公司。即使最后失败,相信也会滋养出更大的辉煌。而一旦成功,便能奠定绝对的市场地位,让其它竞争者难望其项背。
可以看到,学术界的成果和产品之间还有不小的鸿沟。当然其中的因素有很多,如成本、功耗等等,而其中最关键的因素之一是性能。传统的方式很多时候会算法管算法,整好后拿去优化,相互独立,最多整几轮迭代。而今天我们看到,两者需要越来越多地相互融合,共同演进。通过hardware-software co-design才能打造和打磨出更加完美的产品。它需要算法设计中便考虑对于特定平台硬件上的友好性。举例来说,为了更好的部署,网络设计时最好就要考虑哪些算子在目标平台上能被较好地加速;同时训练时加入特定的元素以便于后面的模型剪枝和量化。如果等吭哧吭哧训练了几周,模型都出来了再考虑这些问题就可能会带来巨大的成本。近几年大热的AutoML中的自动神经网络架构搜索(NAS)现在也越来越多地朝着hardware/platform-ware的方向发展。
最后,车辆环境感知中,数据的长尾问题是摆在AD/ADAS面前最大的问题。车辆环境是个开放环境,路上可能碰到任何无法预想的东西。2016年兰德智库指出无人驾驶系统需要进行110亿英里的测试才能达到量产应用条件。显然,这不是几辆车上路满大街跑能搞得定的,传统的测试手段已捉襟见肘。当然,对于ADAS这类驾驶辅助类功能要求会低一些,但本质上面临的问题是类似的。传统的汽车功能安全标准已经无法涵盖这类问题。虽然现在有针对性的预期功能安全(SOTIF)标准正在起草,但其可操作性和有效性还有待验证。总得来说,汽车的智能化给测试验证提出了非常有趣同时也是前所末有的挑战。
